
Introduction
In today’s AI-driven world, developers and businesses are increasingly turning to open-source tools to build scalable and efficient AI applications. From large language models (LLMs) to retrieval-augmented generation (RAG), vector databases, and frontend deployment, open-source solutions provide flexibility, cost-efficiency, and transparency.
The Open-Source AI Stack presented by ByteByteGo serves as an excellent reference architecture, illustrating how different components work together to form a comprehensive AI ecosystem. This blog explores each layer of the stack, highlighting authentic references, real-world use cases, and industry adoption.
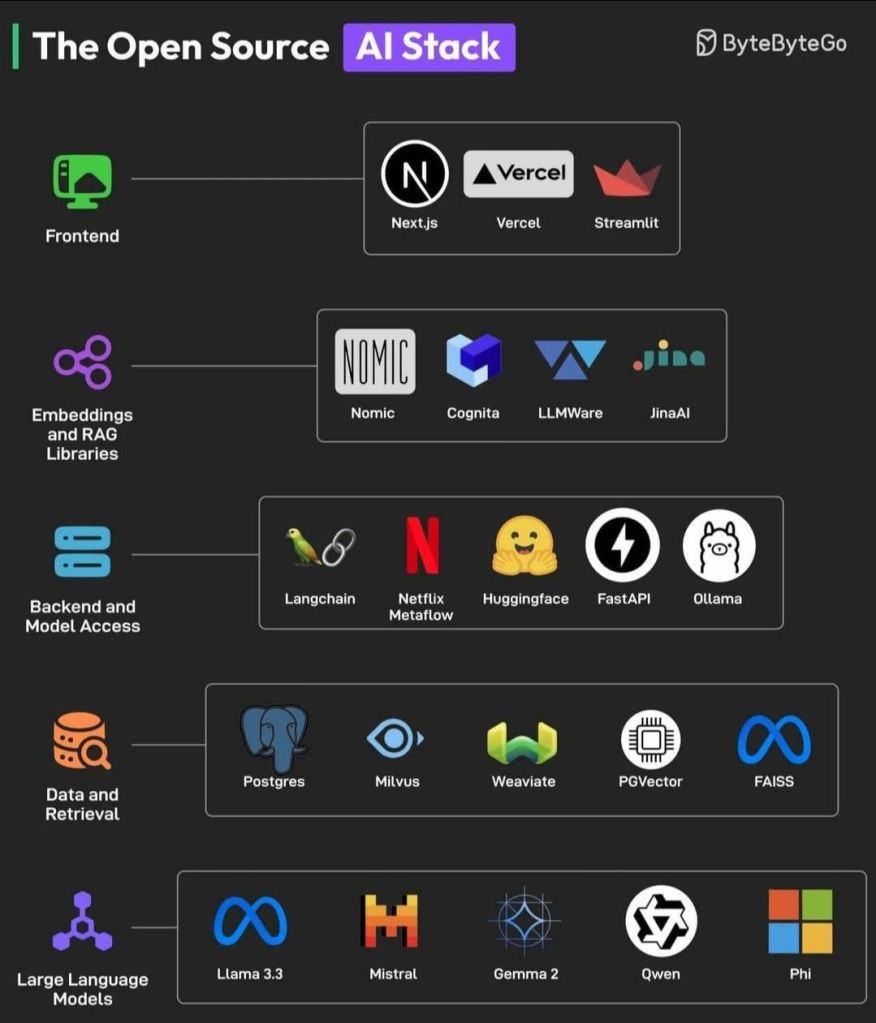
1. Frontend: The User Interface of AI Applications
A well-designed frontend makes AI applications accessible to users. The ByteByteGo stack suggests:
- Next.js (Next.js Official Site) – A powerful React framework optimized for server-side rendering (SSR) and static site generation (SSG).
- Vercel (Vercel Official Site) – A cloud-based deployment platform, ideal for AI-powered web apps.
- Streamlit (Streamlit Official Site) – A Python-based rapid prototyping tool, widely used for ML applications.
Use Case Example:
Imagine an AI-powered personal finance chatbot that suggests investment strategies. Using Next.js for the UI, FastAPI for the backend, and a LLM like Llama 3, the user gets real-time financial insights in a seamless interface.
2. Embeddings & Retrieval-Augmented Generation (RAG)
Embeddings are the DNA of AI models, enabling semantic search, knowledge retrieval, and contextual awareness. The stack includes:
- Nomic (Nomic AI) – Helps in visualizing and managing vector embeddings.
- Cognita – A platform focused on RAG for enterprise search.
- LLMWare – Provides enterprise-level LLM integration.
- JinaAI (Jina AI) – An open-source neural search framework for multimodal retrieval (text, images, videos, audio).
Why RAG Matters?
Traditional LLMs are limited by training cut-off dates. Retrieval-Augmented Generation (RAG) allows LLMs to access live, dynamic knowledge bases, making them more contextually aware.
💡 Example: Imagine a medical AI assistant trained on general medicine. By integrating JinaAI and FAISS, it can retrieve real-time medical journals and research papers, ensuring its responses are up-to-date and reliable.
3. Backend & Model Access: The Brains of AI
This layer connects LLMs with applications and provides API-based access to models. Key tools include:
- LangChain (LangChain Docs) – A framework for chaining AI model responses with memory and logic.
- Netflix Metaflow (Metaflow) – A production-grade AI/ML orchestration system built by Netflix.
- Hugging Face (Hugging Face) – The largest AI model hub, offering pre-trained models.
- FastAPI (FastAPI) – A Python-based high-performance API framework, ideal for serving AI models.
- Ollama (Ollama) – A local runtime for running LLMs on personal machines, ensuring privacy and control.
Example:
A customer support chatbot that integrates LangChain to remember past conversations, Hugging Face’s Llama 3 as the response generator, and FastAPI to serve responses in real-time.
4. Data & Retrieval: The Memory Layer of AI
AI applications require efficient storage and retrieval of knowledge. The stack includes:
- Postgres (PostgreSQL) – A traditional SQL database with AI integrations.
- Milvus (Milvus) – An open-source vector database for large-scale AI search.
- Weaviate (Weaviate) – A vector search engine with semantic retrieval capabilities.
- PGVector (PGVector) – A Postgres extension for vector similarity search.
- FAISS (Facebook FAISS) – A Meta-developed library for high-speed vector search.
Use Case:
Imagine Spotify’s AI music recommendation engine. Using Milvus and FAISS, the system finds songs similar to what a user likes based on vector embeddings.
5. Large Language Models (LLMs): The Core Intelligence
LLMs generate human-like responses and form the backbone of AI-powered systems. The stack highlights:
- Llama 3.3 (Meta AI) – Meta’s open-source AI model.
- Mistral (Mistral AI) – An efficient, high-performance LLM for enterprise applications.
- Gemma 2 (Google Gemma) – A Google-developed AI assistant model.
- Qwen (Alibaba Cloud) – Alibaba’s open-source LLM, optimized for multilingual AI.
- Phi (Microsoft Research) – A small, reasoning-optimized LLM from Microsoft.
Use Case:
A multilingual customer service chatbot powered by Qwen (for multilingual support), Mistral (for fast responses), and Gemma 2 (for knowledge-based queries).
Conclusion: The Future of Open-Source AI
This reference architecture is a blueprint for AI developers, allowing them to build scalable, efficient, and explainable AI systems using open-source tools.
Why Open-Source AI?
✔ Transparency – No hidden biases, unlike closed models.
✔ Flexibility – Customize AI applications as per need.
✔ Cost-Effective – Avoid vendor lock-in and licensing fees.
✔ Community-Driven – Faster innovation through collective efforts.
🔹 AI’s future is open-source. Companies like Meta, Google, and Microsoft are actively contributing models and frameworks, making AI more accessible than ever. Whether you’re building a chatbot, a search engine, or an AI-powered recommendation system, this stack provides the essential building blocks.
🚀 What’s next?
As AI evolves, new open-source models, databases, and frameworks will continue to emerge. Keeping up with these innovations ensures AI remains ethical, explainable, and accessible for all.
💡 Have you built something using these tools? Share your experiences in the comments!
References
- ByteByteGo’s AI Stack (https://blog.bytebytego.com/p/ep146-the-open-source-ai-stack)
- LangChain (LangChain Docs)
- Hugging Face Models (huggingface.co)
- FastAPI (FastAPI Docs)
- Meta’s Llama 3 (Meta AI)
- Google Gemma 2 (Google DeepMind)
- Mistral AI (Mistral AI)
- FAISS from Meta (FAISS GitHub)


Leave a comment